Products
Solutions
Resources


Types of validity in statistics explained
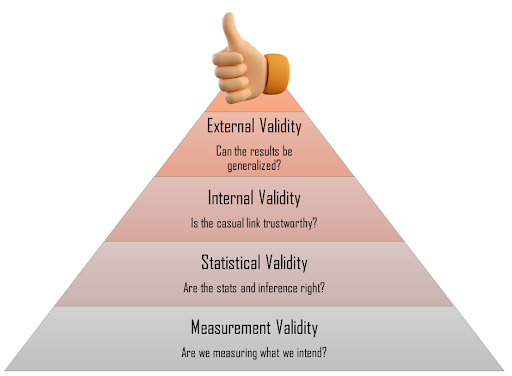
When conducting a statistical analysis, you might find yourself wondering: How much can I really trust these results? The answer often comes down to one essential concept: validity.
Validity refers to how accurately a test measures what it’s intended to measure. In statistics, ensuring validity is crucial for interpreting results with confidence and making informed, data-driven decisions. It helps you avoid costly mistakes and misleading conclusions, whether you're working in product development, healthcare, or any other data-driven field.
At Statsig, we understand just how vital validity is. That’s why we’re committed to helping you design experiments that yield trustworthy, actionable results. In this blog, we’ll break down the different types of validity in statistics, from ensuring your findings reflect real-world behavior to understanding whether they generalize beyond your test environment. Let’s dive in and make sense of it all!
Internal Validity
Internal validity is all about confidence, specifically, how confident you can be that the changes you observe in your experiment are truly caused by the variables you’re testing, and not by outside influences. In statistics, high internal validity means your study is well-controlled, free from confounding factors, and designed to isolate cause and effect. It’s the foundation of any trustworthy experiment. Without it, you might draw conclusions from noise rather than signal, leading to faulty insights and poor decisions. Whether you're A/B testing a product feature or running a clinical trial, internal validity is what ensures your results reflect real causality, not coincidence.
Achieving strong internal validity starts with sound experimental practices. Techniques like randomization (ensuring participants are assigned to conditions in a comparable, unbiased way) and blinding (keeping participants or experimenters unaware of group assignments) are key to minimizing bias and avoiding confounding factors. These methods help ensure that any observed effects are truly due to the intervention, not external influences. At Statsig, we enhance this process by using advanced randomization techniques that maximize the similarity between groups, improving the reliability of your results. It’s also worth noting that in A/B testing, blinding often comes built-in: participants typically aren’t aware of which version they’re exposed to, which helps reduce bias and isolate true causal impact.
External Validity
External validity refers to how well the results of a study generalize beyond the specific conditions of the experiment. In other words, it asks: Do these findings apply to other people, settings, or times? High external validity means your conclusions can be trusted to hold up in the real world—not just within the controlled boundaries of your test environment. Achieving this requires careful attention to how participants are selected, how realistic your testing conditions are, and whether the behaviors you're measuring reflect real-world actions.
A key component of external validity is ecological validity, which focuses on how closely your study mirrors natural settings and behaviors. If your goal is to inform practical, real-world decisions, ecological validity becomes essential—ensuring your findings are not only statistically sound but contextually relevant. For example, A/B testing often has high ecological validity, since experiments are typically embedded within the actual product environment, capturing authentic user behavior.
It’s important to note that internal and external validity don’t always go hand in hand. High internal validity strengthens confidence that your results are caused by the variables you tested, but it often comes at the cost of tightly controlled conditions that may reduce generalizability. Striking the right balance between the two is a central challenge in experimental design, one that determines whether your results are both credible and useful.
Statistical Validity
Statistical validity refers to the appropriateness of the statistical methods applied in a study and the extent to which the conclusions drawn from the data are well justified. Ensuring statistical validity requires that the analysis is conducted correctly and that the methods used to produce results are accurate. When these conditions are met, the findings can be confidently interpreted as true reflections of the relationships or effects under investigation, rather than artifacts of flawed analysis.
Several common issues can compromise statistical validity by increasing the risk of errors. One such issue is low statistical power, which occurs when the sample size is insufficient to reliably detect an existing effect. In these situations, a study may fail to find a significant result, not because the effect is absent, but because the test lacks adequate power. Consequently, concluding that no effect exists is invalid due to inadequate sample size planning. Another frequent problem is multiple testing, where numerous statistical tests are performed without proper correction. Since standard tests assume a controlled error rate for a single test, conducting multiple tests without adjustment inflates the chance of false positive findings.
In both cases, recognizing and addressing these threats is essential to produce statistical conclusions that are trustworthy and meaningful.
Measurement Validity
Measurement validity refers to how well a test or instrument measures what it is intended to measure. Several key types of validity help ensure this:
Construct validity: evaluates whether a test truly captures the theoretical concept it aims to assess, ensuring the tool reflects the phenomenon under study.
Content validity: examines whether the measure comprehensively covers all aspects of the construct, often relying on expert judgment and thorough review of relevant literature.
Criterion validity: assesses the extent to which a measure correlates with or predicts an external outcome, including concurrent validity (correlation with a criterion measured simultaneously) and predictive validity (ability to forecast future outcomes).
Understanding and establishing these forms of validity are essential for designing robust tests, as they build confidence that findings accurately represent the constructs studied and can be meaningfully applied in real-world contexts. Ultimately, measurement validity is foundational for drawing reliable conclusions and making informed, data-driven decisions.
From Theory to Practice
Understanding and ensuring validity in statistical research isn’t just for statisticians, it’s essential for anyone relying on data to make decisions. By focusing on the different types of validity and how to enhance them, you set yourself up for success. At Statsig, we’re all about helping you enhance validity in your studies. With our tools and insights, designing valid experiments becomes a breeze, supporting you in achieving results you can trust. Here are some tips to boost your study’s validity:
Internal validity: Employ randomization and try to control for possible confounding variables. You can implement strategies like A/A tests to validate your systems and detect errors.
External validity: Use representative sampling. Carefully select diverse samples that truly reflect your target population. Try that the experiment context mimics the real context as best as you can.
Statistical validity: This one’s crucial for reliable data interpretation. Use appropriate methods, consider your sample sizes, and avoid premature data peeking to keep your insights accurate.
Construct and content validity: Clearly define the constructs you’re measuring and make sure you cover all relevant domains.
We hope this blog and tips can help you achieve valid results. And remember, Statsig is always here to support you in designing experiments that lead to trustworthy, actionable insights. Hope you found this useful!