Products
Solutions
Resources

Early this year, we shipped Statsig Server Core – our rewrite of our Server SDKs with a shared Rust evaluation engine. The goal was simple: optimize a single codebase and see the results across every server SDK.
One focus area was memory usage. We wanted Server Core's footprint to match or beat our legacy SDKs. To stress test performance, we inflated the test "config spec" payload — the file containing all experiment and feature flag values. At 62 MB, this was much larger than what most customers see, but big enough to reveal bottlenecks. We then compared:
Our Legacy Statsig Python SDK at version 0.64.0
Our Server Core Python SDK at version 0.2.0 (before memory optimizations)
Our Server Core Python SDK at version 0.9.3 (latest optimizations)
We ran Python benchmarks with memray. All of our memory charts show both Heap memory (what the program thinks it's using) and Resident memory (the physical RAM occupied with all the overhead).
Baseline profiling
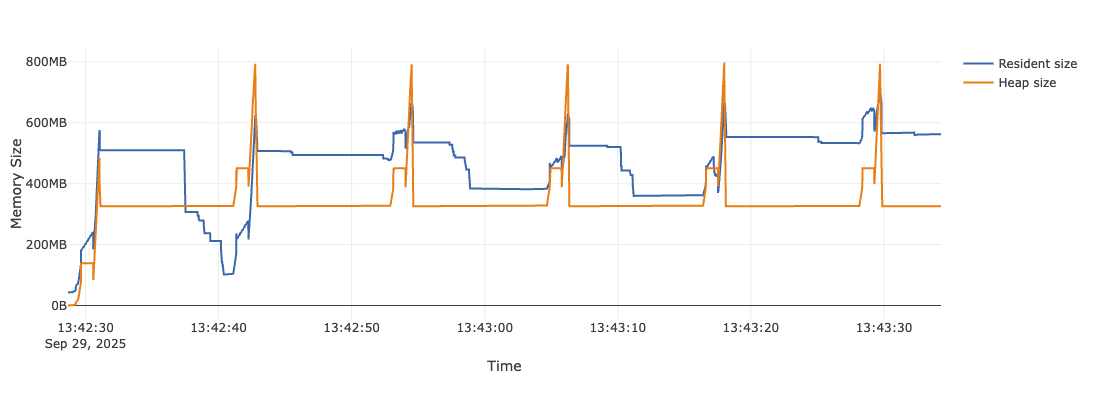
Legacy Python v0.64.0
Legacy Python is the original Python SDK at Statsig — first released when the company was founded in 2021. While we've done some optimizations over time, the SDK shows modest growth, with spikes when the "config spec" is synced with the network, every ten seconds. With this huge, 60+ Mb config spec, memory usage plateaued around 300-400MB.
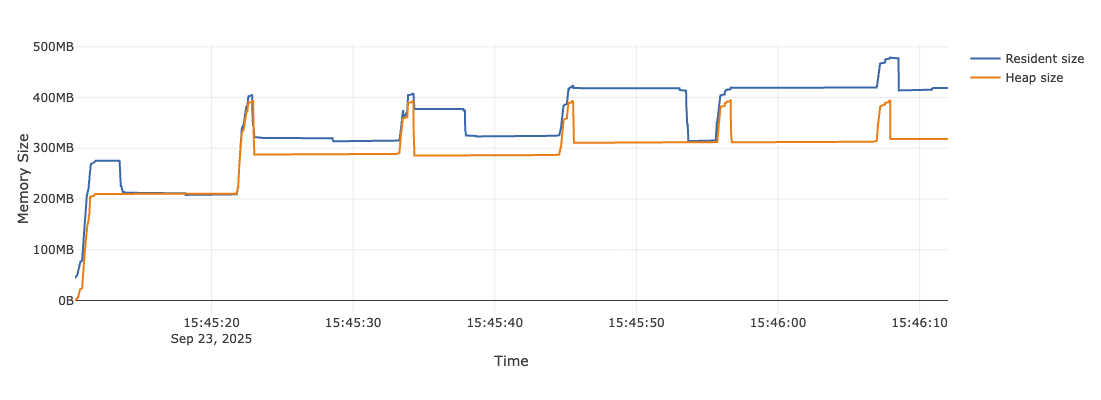
Server Core v0.2.0
When we first launched Server Core, we hadn't yet invested the time to improve memory. The spikes in memory were sharper and up to 800Mb. The volatility in the chart was scary, and the legacy SDK still looked preferable.
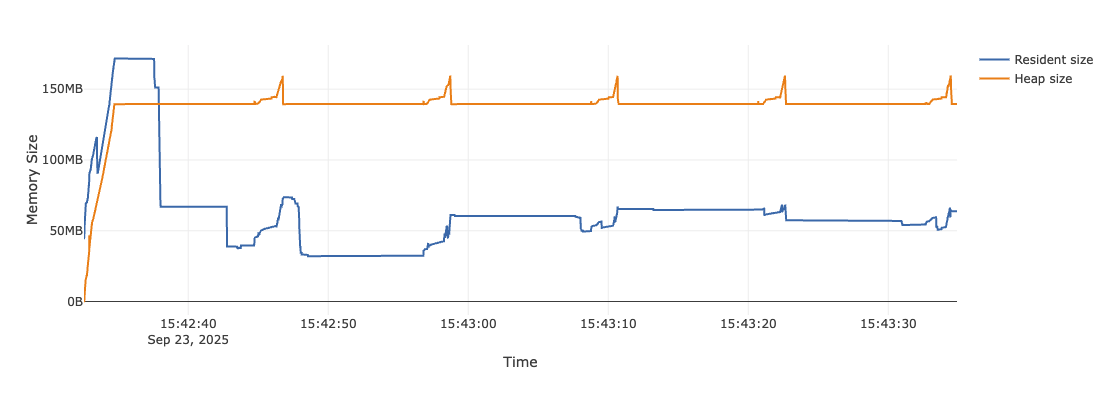
The optimized version
Server Core 0.9.3
After months spent optimizing the SDK, memory usage dropped dramatically to 50-150Mb Resident and 100-150Mb Heap with a few scary spikes.
From old-to-new Server Core, the baseline memory usage is 8–12× smaller (350–450 MB → ~40 MB), while the Peak is 5-6x smaller (700–800 MB → 120–150 MB). Versus the old SDK, the baseline is 5–8× smaller (250 MB → ~40 MB), while the Peak is 3–4× smaller (400–450 MB → 120–150 MB).
Overall, Core 0.9.3 is about 84% smaller at baseline and 68% smaller at peak compared to Legacy.
Finding the bottlenecks
To understand where memory went, we profiled at the Rust layer using cargo-instruments. Unsurprisingly, most allocations were tied to the SpecsResponseFull struct, which holds deserialized JSON for gates, configs, and layers.
We had two key findings:
Strings consumed 56 MB.
Repeated values like "idType": "userID" appeared thousands of times.
DynamicReturnable objects consumed 69 MB.
They were often duplicated across experiments and layers.
The fixes
1. String Interning
We introduced InternedString, a struct that lets us store one reference to a single string, rather than thousands of "userID" copies. This update does two things:
Cuts memory
Makes cloning cheap (critical for when the SDK logs exposures, where strings can be repeated frequently).
2. Shared DynamicReturnable
We applied the same idea to DynamicReturnable objects, which often repeat in responses.
3. Streaming Deserialization
Instead of loading entire JSON blobs into memory, we:
Stream data with reqwest
Use tempfile when payloads exceed 2 MB.
Deserialize with serde_json::from_reader
This avoids 2× memory spikes when syncing new configs.
Future work
Statsig Server SDKs let you convert a User Agent into more convenient browser & OS names and versions, using a User Agent parser. Regex-based UA parsing consumed ~42 MB in the baseline. Today, this can be turned off via StatsigOptions (the disableUserAgentParsing flag), but at the cost of being able to target Devices/Browsers at all.
In a future blog, we will cover the work being done to rewrite the entire UA parser stack to avoid paying this memory cost
Why this matters
Because Server Core is implemented once in Rust and wrapped across languages, the improvements cascade to every SDK backed by Server Core – Java, Node, PHP, and more. Instead of tuning N different SDKs, we make one optimization in Rust and ship the benefits everywhere.
Proof Point: The Server Core Bet
The shift from language-specific SDKs to a unified Rust core is validated here:
Smaller memory footprint across environments.
Faster, more efficient cloning and exposure tracking.
Lower operational cost for customers running large payloads.
Server Core is leaner, more scalable, and more maintainable.