Products
Solutions
Resources

Building good experimentation culture is harder than picking (or building) an experimentation tool.
This is the opinion I've formed from talking to hundreds of product experimenters over the last two years.
People bootstrapping new experimentation programs worry about the more academic issues—the tradeoffs between Z tests and Chi-squared tests or Bayesian vs Frequentist approaches to statistics.
Those already running hundreds of tests worry about more "practical" issues—how can experimenters learn when they violate best practices, how can they get feedback when they pick poor metrics to experiment on, how can they learn to use the experimentation tool well?

What can we learn from manager training?
We can take a lesson from how modern companies approach manager training.
The most effective manager training is often the performance review process where managers get together to "calibrate" expectations. People assume it's the employees that are getting calibrated, but the reality is it's the managers that are being calibrated on how to measure performance.
Managers share how they intend to evaluate their employees based on what they see, and peers provide feedback or critique to make sure expectations are similar across teams. This is how organizations most tangibly help managers learn what behavior and outcomes are valued, and what tools they have available to grow employees.
This is more valuable than any manager 101 training an organization offers.
Bayesian A/B test calculator

What can we learn from the scientific method?
The scientific method recognizes that confirmation bias is powerful. When there is a lot of data, it is easy to cherry-pick test results to find some that support your pet hypothesis.
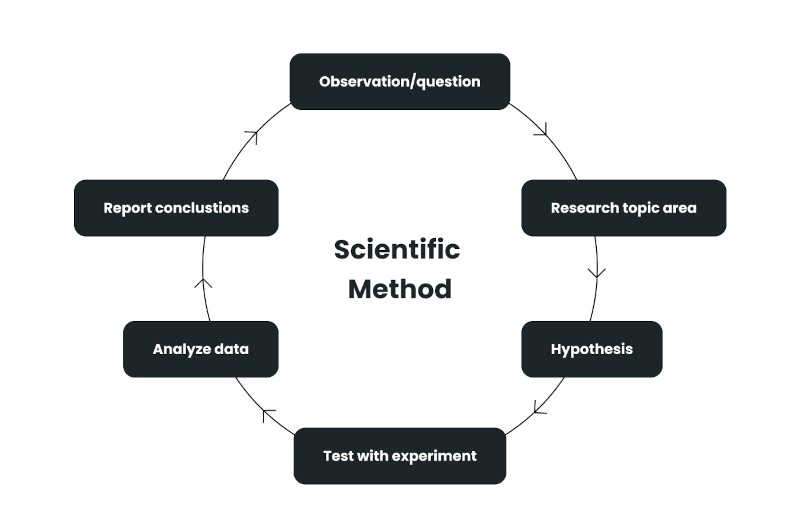
The scientific method addresses this by bringing skepticism. You develop a conjecture, confirm via experimentation, and open this to peer review and critique to make sure you're not missing anything.
Experiment review culture
Experimenters learn by doing. Companies like Meta or Amazon have established experiment review practices, similar to how they formalize code review practices.
Experimenters write up what they plan (before the experiment starts), and capture what they observed and concluded (after the experiment completes). Both of these are critiqued by peers, including strong experimenters in the domain. Through this, the organization disseminates best practices, distributes tribal knowledge, and builds organizational learning.
⭐ Bonus: Try our experiment review template.
Critique
Similar to code reviews, part of experiment review culture is getting people not attached to the experiment to review them. Reviewers also have diverse experiences that expand the perspective that people closest to the experiment might have. Critical lenses they bring include:
Is the metric movement explainable? (Is there a plausible explanation? e.g. did revenue/order go up because we’re recommending higher value items, or because the experiment is causing low-value orders to reduce?)
Are all significant movements reported, not only the positive ones? (Confirmation bias makes it easier to see the impacts we want to see)
Are guardrail metrics violated? Are there costs/tradeoffs we're incurring?
Is the experiment driving the outcome we want? (Once measures turn into goals, it’s possible to incent undesirable behavior; see the Hanoi Rat Problem for an interesting example)
Guarding against p-hacking (or selective reporting). Experimenters often establish guidelines like using ~14-day windows to report results over.
Further reading: Learn how to experiment safely.
The composition of the review group drives how effectively they represent these lenses. Many experimentation groups feature an experienced software engineer and a data scientist familiar with the area that can help represent these perspectives.
They also have a sense of history, and when to ignore this history (hence one of Statsig’s golden rules, “No Sacred Cats.”)
Writing is thinking
Effective online and offline reviews require a culture of writing the experiment proposal, learning, and next steps. This requires investment by the experiment owner; but your ability to have people critically reason and share learning and insights across the organization multiplies when you do this.
Get a free account

Build a learning organization
A key outcome from running experiments is building insight and learning, that persist well past the individual experiment or feature. These insights help shape priorities, suggest ideas for future explorations and help evolve guardrail metrics. Many of these insights seem obvious with hindsight.
Examples of widely established insights that teams have accumulated:
Amazon famously reduced distractions during checkout flows to improve conversion. This is a pattern that most e-commerce sites now optimize for.
Very low latency messaging notifications and the little “so-and-so is typing” indicators dramatically increase messaging volumes in person-to-person messaging. A user who’s just sent a message is likely to wait and continue the conversation instead of putting their phone away if they know the other party is actively typing a response.
Facebook famously found getting a new user to 7 friends in their first 10 days was a key insight to getting to a billion users. With hindsight, it's obvious that a user that experiences this is more likely to see a meaningful feed with things that keep them coming back.
Even when things don’t go well, it’s useful to capture learning. Ran an experiment that tanked key metrics? Fantastic — you’ve found something that struck a nerve with your users. That too can help inform your path ahead!
Ultimately, experimentation is a means to building a learning organization, and we’ve noticed that our most successful experimenters all share this attitude.
Do you have a fun story on something you’ve learned? Let us know, we’d love to hear from you!
Statsig's refer-a-friend program
