Products
Solutions
Resources


"Move Fast and Break Things" has long been associated with fast-paced innovation.
As a team primarily composed of former Facebook employees, we’re well-versed in this motto. In fact, we are often commended by our users as one of the fastest-moving product and engineering teams.
In the meantime, we also understand the importance of providing a stable service, as it is a crucial part of our users' infrastructure. As a young team, we have been refining our software release process to ensure both speed and reliability. This article explores what we’ve learned along the way.
🤖 You can never trust humans
In early 2021, when a team of eight engineers founded Statsig, the focus was on understanding user needs and developing the initial Statsig platform.
While necessary, software release was not the most exciting part of the work, as is common for startups at this stage. At Statsig, we like to have fun.
The team turned the daily release process into an in-office party. The oncall engineer would play some "push songs" on the office speakers and then initiate the release script from their local workstation. Meanwhile, everyone else would take a quick break, enjoy the energized atmosphere, and also monitor the dashboards for any metrics anomalies.
Not long after, we realized that our current release process is precarious and unsustainable as we started acquiring more users on our platform.
It's not because we don't enjoy playing push songs (in fact, it's still a tradition at Statsig), but because humans are prone to errors—moreso than you might think. Even a seemingly simple task like running a release script involves many subtle details that people can easily overlook, such as ensuring the local branch is up-to-date and verifying the release version and candidate.
Additionally, the effort required to mitigate and fix human errors afterward should not be underestimated. This problem became even more significant given our fast iteration speed: We strive to deliver improvements and new features to our users quickly, but those users are also counting on us to deliver a stable platform.
Fortunately, the infrastructure footprint was relatively small at the time. We quickly transitioned from a prescriptive deployment model to a declarative manifest model, adopting the cloud-native GitOps practice. Instead of prescribing how to release, the oncall engineer now only needs to decide what to release on a daily basis.
Steps for each release are defined as rules and implemented by the software (we use ArgoCD and Argo Rollouts for our releases). Since then, the lives of oncall engineers have improved significantly—and more importantly, we have greatly reduced the number of incidents caused by our daily releases.
Let’s take full control of the entire release
Adopting GitOps is just one piece of the puzzle.
The entire team is responsible for the release process—many sub-teams are involved before, during, and after the release. Successful releases depend on engineers knowing what to look for and what to do when things go wrong.
There are numerous articles discussing the best practices for releasing software. Depending on the software's stage and the engineering team, different aspects of the process should be emphasized.
As an early and lean engineering team, we have consistently adhered to a few basic and critical building blocks since the beginning, regardless of how the processes have evolved.
Metrics
At Statsig, metrics are central to our offerings and beliefs. While metrics can sometimes be misleading, well-defined metrics can save engineers time and effort by allowing them to focus on the most important areas.
Consequently, we invest a significant amount of time in cherry-picking the most critical metrics that we prioritize. We learn from these metrics and continuously evolve them, aiming to avoid noise and ensure that they provide clear signals during releases.
Canary rollouts
Canary rollouts are a valuable companion for a fast-paced engineering team, and we are a big fan of them here at Statsig.
It involves gradually increasing the percentage of overall traffic that is directed to a new version of the software. This strategy allows different teams to assess the impact of their changes or features before fully rolling them out.
However, as the product becomes more complex and larger in scope, conducting canary rollouts safely can become more challenging. Teams will require assistance from various tools to achieve coordinated and secure canary rollouts. I’ll delve into this topic further in the next section.
Rollback
A successful release plan must include a rollback strategy.
Unfortunately, this is often overlooked, possibly due to the association of rollbacks with mistakes—which humans naturally fear. However, rollbacks should be a normal part of the release process. On one hand, they can help prevent potential bigger losses, and on the other hand, they are common in mature product and engineering teams that prioritize high-level service objectives over individual operational events.
At Statsig, we have developed a rollback system that allows every engineer to initiate a rollback when unexpected issues arise (which is also possible because we are still a small team!). We’re also currently working towards implementing a more automated system for triggering rollbacks in order to minimize the time that faulty versions are live.
Get a free account

Only release what you are confident about
When discussing with our users and friends, one of the most frequently talked about topics is how to properly implement canary rollouts in releases.
Like other engineering problems, there is no one-size-fits-all solution. A canary rollout strategy should be tailored to the systems it serves, with a clear understanding of the behavior and a specific goal to achieve.
Undoubtedly, canary rollouts can be relatively easy to implement and control when the team is small and the product is in its early stages. In these cases, only a limited number of owners need to fully grasp what to look for when new versions are released.
However, in reality, application systems become more complex and involve many more owners and stakeholders. Therefore, building a canary rollout strategy that works for everyone is a challenging task.
At Statsig, we follow a distributed approach where individual teams or owners are responsible for making their own decisions on canary rollouts. To ensure consistency, we provide a standardized set of tooling across the company. This approach allows everyone to have a shared understanding.
We chose this approach because it is impossible for any individual or team to have complete knowledge of every feature or improvement in the releases, as well as their implications and impacts.
Arguably, some other teams may choose to assign a dedicated release engineer for each release, but this approach is not suitable for us. It could slow down our development velocity and introduce potential single points of failure. It would also involve more teams when issues arise.
To accomplish this, we utilize several deployment tools and feature gating/experimentation in our stack. And yes, you guessed right! We use Statsig to release Statsig. Here are some details on how we implement it:
Every feature owned and developed by an engineer needs to be guarded with feature gates and/or implemented as an experiment. The engineer is also responsible for selecting the metrics that are critical for the feature.
Oncall engineers deploy new binaries on a daily basis. As part of this deployment process, a canary rollout is implemented at the traffic routing level. Special attention is given to system-level metrics, such as API success, latency, event volume, CPU usage, and memory usage, which may be affected by the new binary versions. This approach offers several benefits:
Oncall engineers have more specific signals to monitor during the rollout.
Features rolled out afterward have a baseline to reference.
The separation of different types of rollouts enables easier monitoring and troubleshooting in case of issues.
Once the system-level rollout is complete, feature owners initiate the gradual rollout process of their respective features. They do this based on their own strategy to understand the impact their features will have.
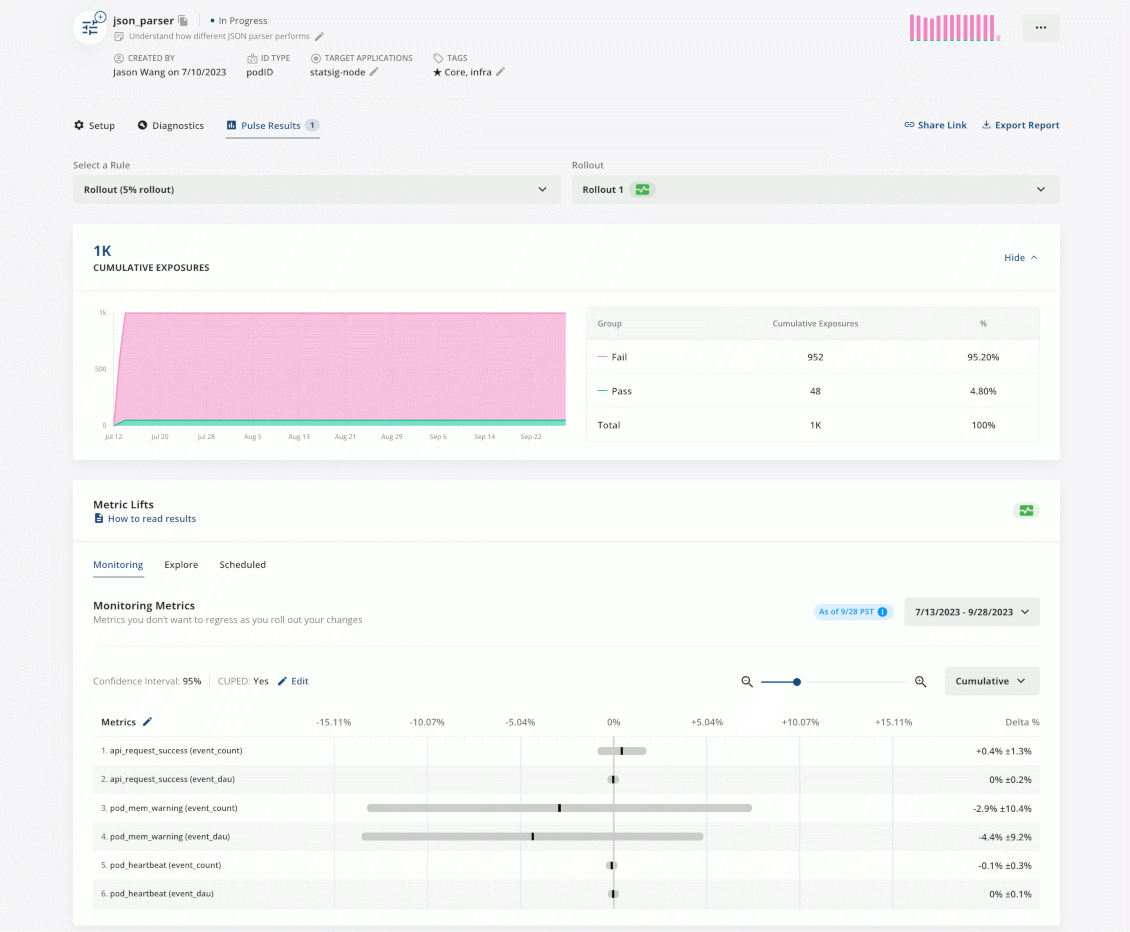
With the help of the tools and the process, teams at Statsig are always empowered to confidently release with their own schedule. Embracing this process has improved the reliability of our product and reduced incidents.
We’re still just at the beginning of the journey. As we continue to build out our platform, we're not just helping our users, but we're constantly evolving, adopting industry standards, and learning together.
🤔Got thoughts on release safety, or how we operate? Drop me a line at jason[at]statsig.com.
Keep experimenting, and catch us on statsig.com or our Slack.
Join the Slack community

(Thanks Tore Hanssen for the input and collaboration on this article!)