Products
Solutions
Resources



Generative AI applications have taken the world by storm.
While generative AI has been useful for several years, the performance of the latest generation of large foundation models (like OpenAI’s ChatGPT) has dramatically expanded the number of people building with AI. There are seemingly endless opportunities to build amazing apps.
As an experimentation provider, we’ve seen an influx of customers wanting to experiment with generative AI apps. Captions, for example, tested OpenAI’s Whisper against Google’s text-to-speech API. Other customers—like WhatNot and Notion—have used Statsig to deploy and refine AI-based features.
Our team dug in to understand how easy experimentation can be when Statsig is combined with the latest generation of foundation models.
Read on to learn:
Why experimentation matters for generative AI apps
How to use Statsig to experiment with generative AI (with an example app)
Why Statsig can be a game changer for AI developers
Why does experimentation matter for generative AI apps?
Experimentation was critical to the last generation of great technology companies.
It’s not an accident that many of the biggest Web 1.0 and Web 2.0 success stories—Facebook, Netflix, Uber, Amazon, Airbnb—are known for their cultures of experimentation. In a world where technology is built with ‘black box’ foundation models rather than descriptive code, great experimentation tools will become even more important.
Before generative AI, engineers understood the specific feature they were shipping, even if they didn’t always know the impact the feature would have. Since you could see a static ‘before and after’, intuition could drive product improvements: A good PM could ‘know’ that shipping a great feature was likely to increase user metrics, a great company would use experimentation to make sure it did.
With foundation models, it’s much harder to have this type of intuition.
An engineer can make tweaks to model parameters and do an ‘eye test’ for output quality, but how do you know that this quality will translate to thousands of users entering different inputs? Historically, the answer has been either using data labeling providers to test response quality (expensive) or shipping and seeing what happens (risky).
In the long run, the only answer is experimentation. Unfortunately, good experimentation is hard to set up and configure—which is where Statsig comes in.
How to use Statsig to experiment with generative AI
To illustrate how easy it is to experiment with generative AI apps using Statsig, our team built a sample web app written in reactJS: “Statsaid.”
The app is built using OpenAI’s API, and designed to answer short user questions about Statsig.
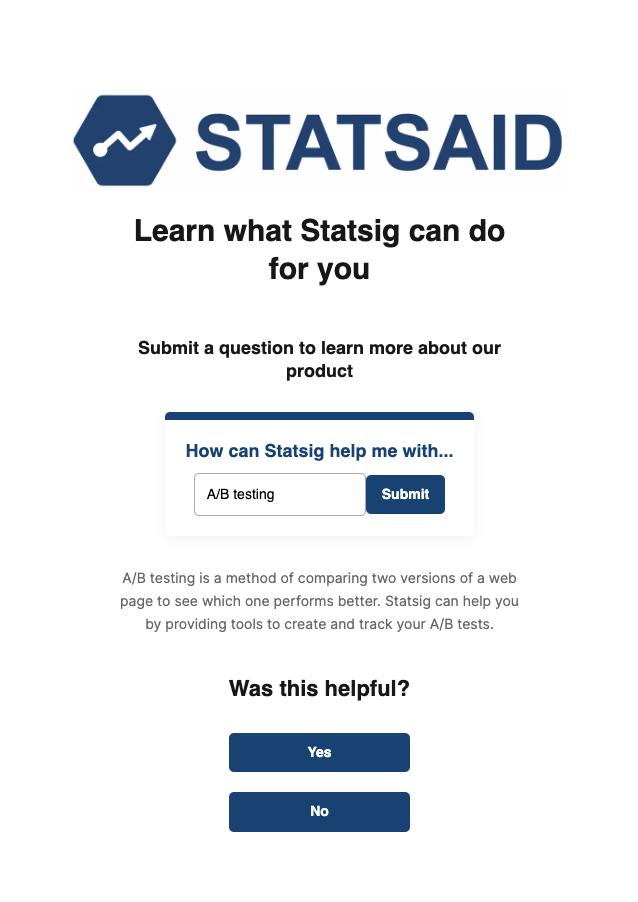
In Statsaid, users submit a short input (e.g., “A/B testing”) which is combined with an underlying prompt (e.g., “write a 50-word response describing how Statsig can help me with…”) and sent into OpenAI’s API. The user sees the output below the input box, and is prompted to share if the response is helpful or not.
Below, we’ll demonstrate how we used Statsig to set up an experiment on this app. In this example, we’re assuming you have already set up Statsig’s SDK plus any foundation model APIs you’ll be using.
Step 1: Variabilize core model parameters
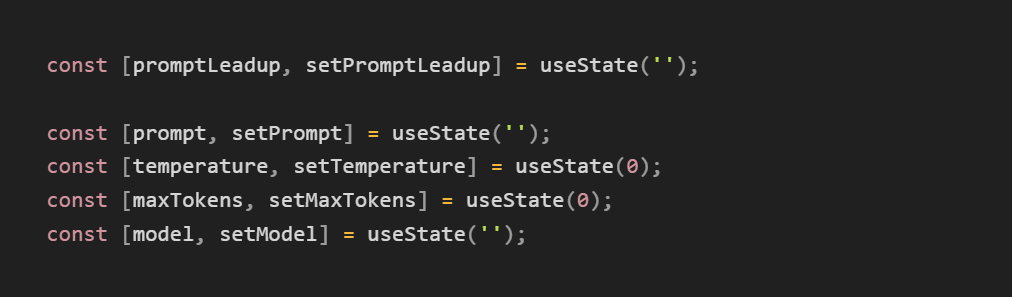
OpenAI’s API has four primary parameter inputs: model, prompt, temperature, and max_tokens. To experiment with these inputs, we need to declare variables for each of them. Later, we’ll set the value of these variables using Statsig.
Since users are going to be entering an input, we split the prompt into two sections: promptLeadup (a short string that provides instructions to the model) and prompt (the final prompt, which combines promptLeadup with the user input). We also declared variables for model, temperature, and max_tokens.
Step 2: Set up an experiment using these variables
Our baseline app was built using the following parameters:
Prompt: “Write a 100-word response to the following question. If the question is unrelated to statistics or Statsig, please respond: Sorry, Statsig cannot help you with that. Question to answer: How can statsig help me with [user input]”
Temperature: 0.1
max_tokens: 300
Model: text-davinci-003
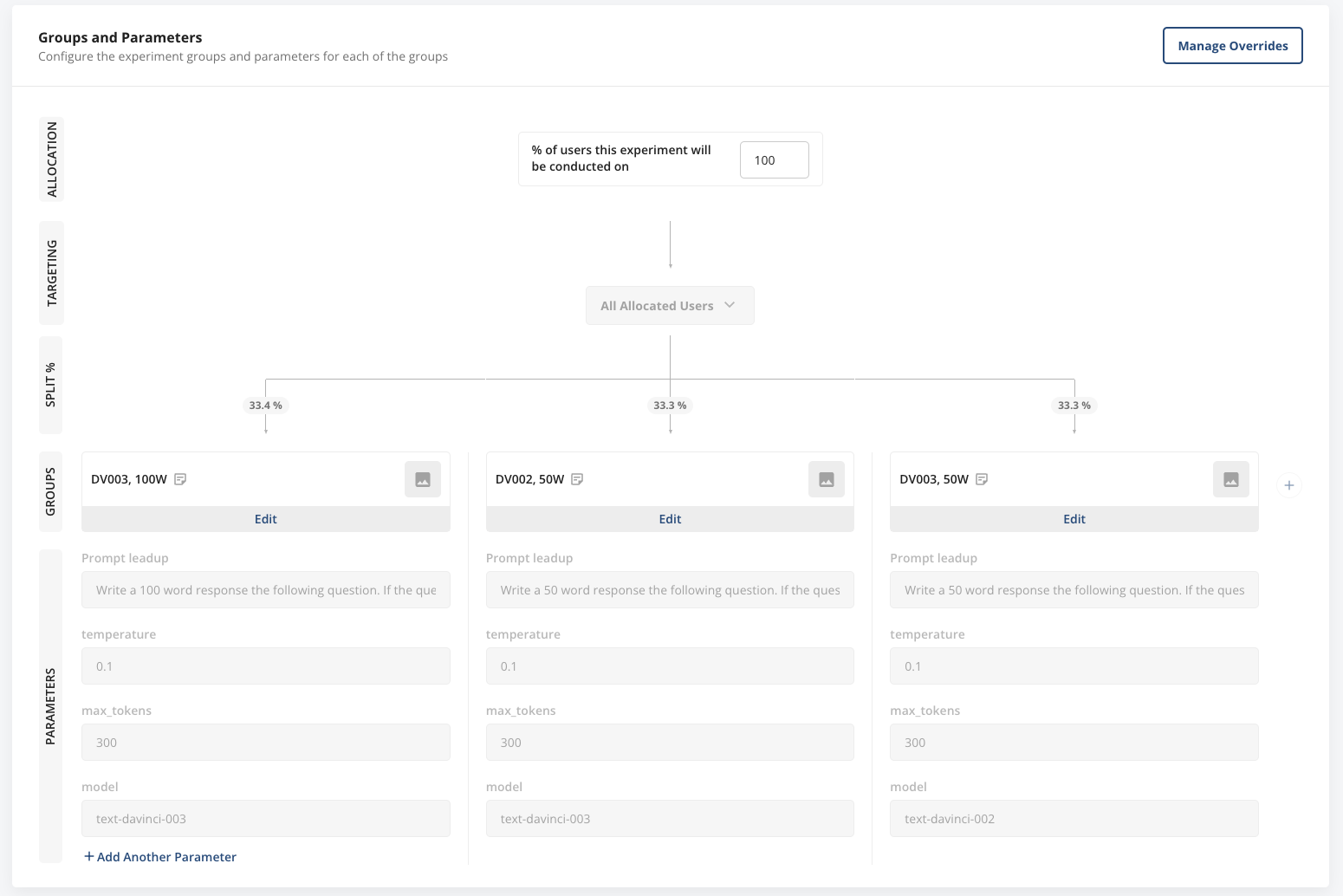
For this example, let’s say our product team had a hypothesis that decreasing word count would improve user engagement and clicks of the ‘was helpful’ button, because the answers were concise. They also wanted to try using the davinci-002 model, to see if that made a difference. To test this, we set up an experiment on Statsig.
We decided to allocate 100% of our users to this experiment, across three variants—one with a 50-word prompt using davinci-002, and one with a 50-word prompt using davinci-003. In the experiment layout (below) we’ve changed both of these parameters. Normally, we wouldn’t include the other parameters (temperature and max_tokens), but we left them in to demonstrate the capability of our platform.
Join the Slack community

Step 3: Load these values in, and pass them into the foundation model API
Next, we loaded these values from Statsig using the Javascript SDK, and passed these values into OpenAI’s API.
Once we start the experiment, users will be assigned automatically to the four treatments:

Step 4: Configure event logs
Finally, we need to configure log events for this prompt. In this case, we’re adding log events for the model, the prompt, temperature, max tokens, choice (the model output), finish reason, and the number of tokens used.
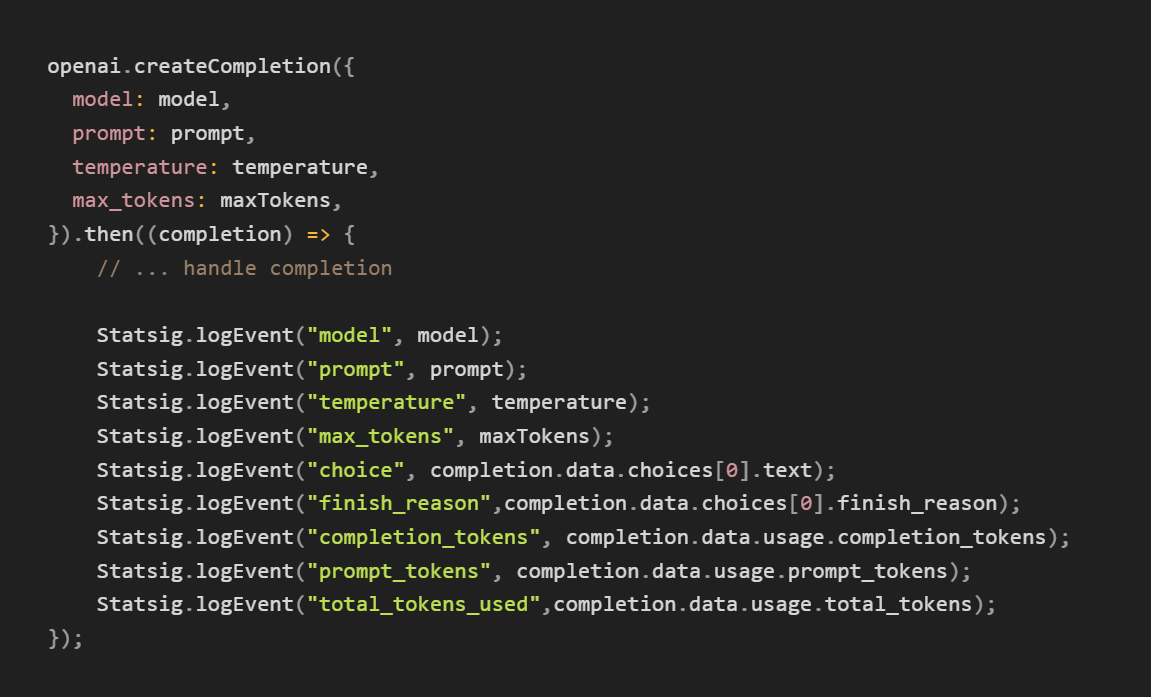
You can add log events for any metric you’re tracking to measure model efficacy, including latency, cost, plus user inputs (e.g., “Was this helpful?” buttons). These will be shown in the experiment results and metrics tab alongside default user metrics (e.g., DAU, WAU, MAU, stickiness, etc.) and any other metrics you’re tracking. In the long run, this log can be used as a ‘data store’ for comparing model results.
Step 5: Check results
Once the experiment is running for a day, you’ll see all the metric values populate in the Pulse tab.
Related: Read the documentation on interpreting Pulse results.
Since this wasn’t a production app, we didn’t have enough user volume to produce statistically significant results (our ~15 in-house testers weren’t enough, unfortunately). We did generate some response data to show the type of results one can get with Statsig.
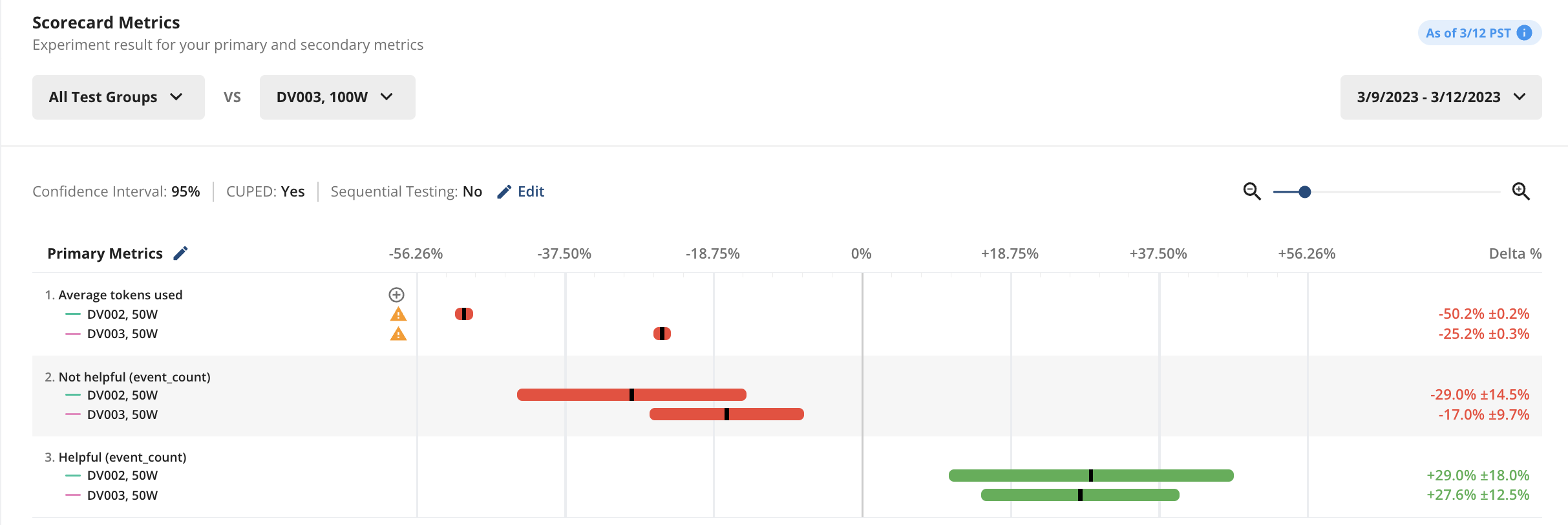
If this were real data, these results would imply that both 50-word prompts drove a statistically significant ('statsig') reduction in token use, a statsig reduction in ‘not helpful’ clicks, and a statsig increase in ‘helpful’ clicks. In a production app, you would be able to check these ‘primary metrics’ against all other user metrics you track, to ensure there weren’t unintended consequences on other user behaviors.
Once we have enough data to make a decision, we’ll choose a model to commit to our code. From there, we’re off to the next experiment.
Why Statsig can be a game changer for AI developers
Statsig was built as a general-purpose feature management and experimentation platform, giving anyone access to the kind of sophisticated development tools available at Facebook, Netflix, or Uber. While Statsig can make any developer’s life easier at any layer in the AI application stack, Statsig can be revolutionary for developers building on top of foundation models.
For starters, Statsig allows anyone to simultaneously test the impact of changes to an app and changes to a foundation model. A developer can easily run an experiment where they change the title of a page and the prompt submitted to a foundation model.
The ability to orchestrate these at the same time in the same platform and quantify the impact of each of these changes is critical when building AI-enabled applications.
Statsig also allows builders to compare the efficacy of multiple foundation models (or multiple versions of the same model) in one experiment.
You can easily run an experiment where OpenAI’s API is used to generate responses for one group of users and AI21’s API is used to generate responses for another. As more companies release foundation models built for specific tasks, this sort of interoperability will be essential.
Finally, Statsig helps developers see the impact of these changes on user and model metrics, at the same time. This type of visibility makes unintended consequences obvious (i.e., we made the model cheaper, but engagement fell off a cliff), and opens up quantifiable tradeoff conversations (i.e., model A costs X% more than model B, but increases engagement rate by Y%). As the products built on top of foundation models become more complex, this clarity allows companies to move fast without breaking things.
Get a free account

More applications, fewer problems
As the use cases for generative AI continue to multiply - spreading from chatbots to marketing copy to synthetic data creation and more - more companies are building on AI models. If you’re a company entering the world of AI apps for the first time, wouldn’t it be nice to roll it out one feature at a time, and back up everything you’re trying with experimental results? We certainly think so.
In the coming weeks, we’ll go on this journey ourselves with an OpenAI-powered support chatbot / Slackbot (thanks to amazing work from an early customer, Alex Boquist). We’re excited to share more on how we use Statsig to make this happen.
Statsig was built to provide amazing tools to people building amazing products. We’re so excited to see the sort of things people are able to create when our platform is combined with the latest generative AI tools.
How Tempo democratizes fitness
