Products
Solutions
Resources



Building complex data products that use user inputs can lead to a tricky development process.
It's not easy to determine what inputs you’ll be getting when you write your code and tests.
There are many tools to solve this high-level problem, with different tradeoffs between safety, complexity, and development speed. At Statsig, we’ve embraced the use of remote-server side configurations (we use our own implementation, called Dynamic Configs) to bootstrap new products and support custom inputs in production code.
There are several advantages of this approach, which I’ll discuss below. In short, Dynamic Configs have given us:
Modularity, sharability, and reusability of hardcoded values
Lightweight code review and deployment for config changes, with a standalone audit log. This democratizes config changes so that non-technical partners can request changes.
Support for arbitrary complexity in production and during the development process
Background
At Statsig, the data science team finds itself in the curious position of being a software development team in its own right.
While we’ll ship the occasional button onto the Statsig console, most of what we’re doing is working with software engineers to exchange payloads of data—whether it’s the console team sending us customers’ metric definitions data source configurations, or us sending the results of statistical analysis to the front end for them to make pretty for the end user.
Sharable and Modular
When we’re developing new features, it’s often concurrent with the Engineering team’s own development. A common issue you’ll run into here is agreeing on the structures we’re handing off. For example, if we’ve agreed that we’ll use MongoDB to store our configs, we need to be prescriptive about what the fields will be in the MongoDB document.
In the past, I’ve seen this done with a desk meeting and drawing out what you’ll use, or waiting for one party to get going and to share what they’ve saved.
With configs, I’ll just start hacking and share the config I’m using. If I update the config, that remains the source of truth. This lets me create a draft of what I’m thinking and keep it current throughout my own process.
For example, let’s say we want to support a new form of custom metric creation. The initial configuration I whip up for testing might look like this:
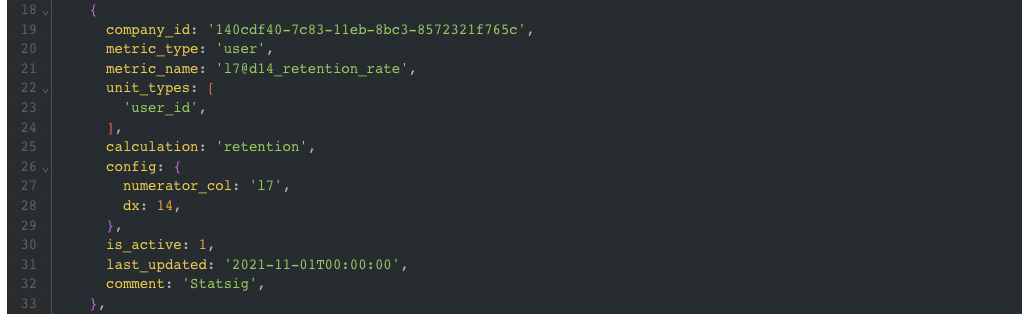
With this value in a dynamic config, I can pull the remote JSON value from the config and then send a link to my engineering partner to show them the exact format I’m using. As we develop, they can start referencing the config themselves.
Even better, they can plug in their own test outputs to this config and run my code to test it without needing to understand my code or publishing their data to a real data store.
This isn’t just a partnership between engineers and data scientists, either; with dynamic configs, any partners - often the sales team and PMs - can also add to configs safely due to the built-in review process.
Reusability
Generally, the data team pulls customer configurations from a production data store. However, Statsig’s pretty scrappy, and we’ll often give customers access to features they need before we have a fully baked UI treatment for it.
In this interim window, we’ve found that it’s really easy for us to set up a dynamic config to hold configurations for the handful of customers we’re working with. Once we have the full feature finished, we swap out the function that accesses the dynamic config to one that accesses a production data store.
This has the advantage of letting us use the same config everywhere in our code as we develop this feature. When we make this swap, we only have to make one change. This is a way better pattern than copying the config across files, and allows us to enforce a soft contract around what the data looks like.
A salient example is that we’ve recently started rolling out support for multiple timezones. This has been a feature the data team’s really excited about, as it allows customers that aren’t in our timezone to get their data in a timely manner. As we developed this, we:
Created a dynamic config that initially just had an allowlist of companies matched to their timezone:

Created a util function which pulled this in our python libraries. This is as simple as:

Referenced this function everywhere in code
As we continued to develop, we realized we needed the ability to set this config before the actual time the company switched timezones (say going from PST to UTC). So, we added an effective timestamp at which the company swaps over:

Updating the logic across 10+ files where we were referencing the new timezones, determining if the company timezone in a date-dependent (and backwards-compatible) way was pretty simple. We only need to change these checks in one place:

Review and Audit Log
Making a code change to update a list of hardcoded values can feel cumbersome and slow for what is generally a non-controversial and safe change. However, we’re generally shy about allowing people to land code changes in our pipelines without any review (for obvious reasons).
Dynamic configs have been really useful for us here as well. In our “Statsig Databricks” project we have fairly lax review rules set—so we ask for review, but you can bypass the process if needed. This means we can quickly update things when needed, but we still get to keep an audit log and have the ability to request a proper review from our teammates.
I want to point out specifically how useful this is for collaboration. In the example of timezones above, Maggie led the charge on most of the initial work and I helped clean up some details around making it work for our data warehouse integrations near the end.
We were able to use this config to keep track of what data we were using and how we were changing it as we both added required fields and test cases.
An unexpected benefit of this is clarity of ownership; it’s really easy to just look up the config in the console and see who’s been touching it, even compared to looking at the git blame.
Support for Arbitrary Complexity
One of the beautiful things about using Dynamic Configs, for us, is that you can support arbitrary complexity (well, so long as it’s JSON-encodable). For example, if there’s a really complex object that we need to start handling for engineers, we can just have them paste an example in a dynamic config and get to hacking on it. We’ve used dynamic configs for:
Configuring a new feature for a handful of customers
Defining custom metric types
Keeping a store of legacy data fields on customer domains that we infrequently access
Saving the non-secret parts of connection configurations for internal usage
We can usually hack in a dynamic config for your first pass at a given use case, and trust that we’ll be able to represent any data model that you plan to make more official in the future.
Home Team Advantage
Lastly, there’s more than one tool out there for pulling remote configurations. The point of this isn’t to point out they exist, but rather that they’re a really neat way to handle collaborating on projects that involve complex/critical data payloads or schemas.
I would have loved to have this at previous roles where I was building metric definitions, or for quickly sharing configurations between my code and engineers’ when prototyping new personalization models.